
Класифікація ґрунтів за допомогою глибокого навчання (Deep Learning)
Посилання на матеріал на github
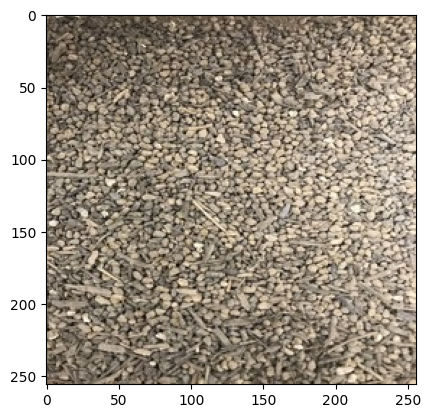
Класифікація ґрунтів може бути важливою задачею для різних галузей, включаючи геотехнічну інженерію, сільськогосподарську науку та будівництво. Хоча існує багато схем класифікації, популярний та інтуїтивно зрозумілий спосіб класифікації ґрунтів базується на розмірі зерен ґрунту, таких як гравій, мул, пісок тощо. Це досить простий спосіб класифікації ґрунтів, оскільки між кожною класифікацією існують чіткі межі. Наприклад, гравій - це будь-яке зерно діаметром понад 2 мм, пісок - від 1/16 мм до 2 мм, а мул/глина - менше 1/16 мм.
© Джерело
Мета
У цьому завданні комп'ютерний зір створює модель класифікації ґрунтів на основі фотографій гравію, піску та мулу. Для класифікації фотографій ґрунтів використовується згорткова (конволюційна) нейронна мережа (CNN).
Ключові поняття:
Аугментація (розширення) даних — це практика, яка часто використовується в класифікації зображень і полягає в збільшенні існуючого набору даних зображень шляхом створення нових наборів даних на основі існуючих. Таке розширення найчастіше застосовується в таких операціях, як зміщення зображення, дзеркальне відображення зображення по горизонталі або вертикалі, збільшення зображення тощо. Ці розширення створюють нові зображення і, таким чином, збільшують кількість зображень для навчання. Детальніше про це читайте в статті Джейсона Браунлі.
Згорткова нейронна мережа (CNN) — популярна модель для класифікації зображень. CNN розрізняють характеристики зображення, проходячи по циклу через значення пікселів у зображенні та обчислюючи скалярний добуток цих пікселів з матрицею фільтра «ядра». Ці матриці ядра підкреслюють різні аспекти зображення, такі як вертикальні та горизонтальні лінії, кривизна тощо. Для отримання додаткової інформації про CNN див. APMonitor — комп'ютерний зір із глибоким навчанням.
| In [3] |
|
Налаштування
Імпортуйте наступні модулі Python. Не забудьте використовувати pip для встановлення будь-яких пакетів, яких вам бракує. Наприклад, якщо ви отримуєте помилку: ModuleNotFoundError: No module named 'cv2', додайте нову клітинку, натиснувши кнопку "+" вище, та виконайте таку команду в іншій клітинці: !pip install opencv-python.
| In [4] |
|
Дані
Дані розділені на каталоги test та train. Папки test та train містять підкаталоги, що відповідають можливим ґрунтам. Позначена деревоподібна структура папок допомагає позначати фотографії для навчання та тестування.
| In [5] |
|
Імпортуйте дані в сеанс Python.
Перший крок – обробити зображення у формат, який
- Робить дані читабельними для моделі
- Надає більше навчального матеріалу для моделі.
Так, змінна training_data_processor масштабує дані так, щоб вони могли бути вхідними даними моделі, але також бере кожне зображення та доповнює його, щоб модель могла навчатися на кількох варіаціях одного й того ж зображення. Вона перевертає його горизонтально, обертає, зміщує тощо, щоб модель навчалася на фотографії ґрунту, а не на орієнтації чи розмірі.
Навіщо? Щоб наша модель стала розумнішою і не "зазубрювала" картинки, а вчилася розпізнавати об'єкти в різних умовах.
Отже, training_data_processor — це наш "креативний" процесор для навчальних (train) матеріалів. Він бере кожне тренувальне зображення і під час тренування щоразу показує моделі його трохи змінену версію, що підвищує її стійкість до нових даних.
При цьому ImageDataGenerator — це клас, який допомагає автоматично змінювати (аугментувати) зображення під час тренування моделі.
Що робить кожен параметр:
rescale = 1./255: Це найважливіший крок. Кожен піксель у кольоровому зображенні має яскравість від 0 (чорний) до 255 (дуже яскравий). Ця команда ділить значення кожного пікселя на 255. В результаті всі значення стають в діапазоні від 0 до 1. Моделям набагато легше працювати з такими маленькими числами.horizontal_flip: Випадково віддзеркалює зображення по горизонталі.zoom_range: Випадково наближує або віддаляє зображення на певний відсоток (%).rotation_range: Випадково повертає зображення на кут до заданої кількості градусів.shear_range: Це "зсув". Уявіть, що ви зсуваєте верхню частину прямокутника, перетворюючи його на паралелограм. Це імітує погляд на об'єкт під кутом.height_shift_rangeтаwidth_shift_range: Трохи зсуває зображення вгору-вниз або вліво-вправо до заданого відсотку.
test_data_processor — це наш "суворий екзаменатор".
Для тестових даних ми НЕ використовуємо аугментацію. Тест — це перевірка того, наскільки добре модель впорається з реальними, незміненими даними. Ми не хочемо давати їй підказки чи спотворювати "екзаменаційні завдання".
Єдине, що ми робимо, — це rescale = 1./255. Чому? Бо модель тренувалася на даних, де пікселі були в діапазоні 0-1. Щоб перевірка була справедливою, тестові дані мають бути в тому ж форматі.
| In [6] |
|
Завантаження зображень із папок
Змінна training_data бере наш креативний процесор (training_data_processor) і застосовує його до зображень з папки training_data_directory.
flow_from_directory— завантажує зображення з папки, автоматично розподіляючи їх по класах (підпапках).training_data_directory— шлях до папки з тренувальними зображеннями.target_size = (256, 256)— всі зображення змінюються до розміру 256x256 пікселів. Нейронні мережі вимагають, щоб усі вхідні зображення були однакового розміру.batch_size = 32— зображення завантажуються порціями по 32 штуки (це зручно для тренування).class_mode = 'categorical'— підходить для задач, де є кілька класів. Автоматично визнача' класи за назвами підпапок (Gravel, Sand, Silt) і перетворювати їх у формат, зрозумілий для моделі (наприклад, [1, 0, 0] для Gravel і [0, 1, 0] для Sand).
Аналогічно для завантаження тестових даних testing_data:
test_data_directory: Шлях до папки test/.shuffle = False: Дуже важливо! Ця команда каже не перемішувати тестові дані. Під час тестування нам часто потрібно знати точні прогнози для кожного конкретного зображення, тому їх порядок має бути сталим. Для тренувальних даних перемішування увімкнене за замовчуванням, що є доброю практикою.
| In [7] |
|
Отже,
- тренувальні дані автоматично змінюються (аугментуються) для кращого навчання моделі
- тестові дані використовуються без змін, лише нормалізуються
- зображення беруться з папок, змінюються до потрібного розміру, групуються по класах і подаються в модель порціями.
Розробка моделі
Наступний крок – побудова моделі згорткової нейронної мережі (CNN). У наступній ячейці встановлюються параметри для побудови моделі. Це включає кількість згорткових шарів, повністю зв'язаних щільних шарів, кількість вузлів у кожному шарі та кількість епох навчання. Для отримання додаткової інформації про ці параметри та згорткові нейронні мережі загалом див. APMonitor - Комп'ютерний зір з глибоким навчанням.
- Параметр
layer_size(розмір шару) має великий вплив на швидкість навчання, точність та розмір моделі. Це – "потужність" або "ширина" наших шарів. Кожен шар матиме певну кількість нейронів (або фільтрів). num_conv_layers(кількість згорткових шарів) - це "очі" нашої моделі, які шукають візерунки на зображенні.num_dense_layers(кількість повнозв’язних шарів) - це "мозок" моделі, який аналізує знайдені візерунки і приймає рішення.num_training_epochs(кількість епох навчання) – відповідає, скільки разів модель повинна "переглянути" всі навчальні зображення. Саме один такий перегляд називається епохою.
| In [8] |
|
Далі ми починаємо "будувати" нашу модель шар за шаром, як поверхи в будинку.
Блок згорткових шарів (аналіз зображення)
Sequential()створює порожній "каркас" для моделі, в який ми будемо послідовно додавати шари.Conv2D(layer_size, (3, 3), input_shape=(256,256, 3))– це перший згортковий шар:
Conv2D: Головний інструмент, який сканує зображення маленьким "віконцем" (фільтром) розміром 3x3 пікселі, щоб знайти прості ознаки (лінії, кути, градієнти).layer_size(32): Ми створюємо 32 таких фільтри, кожен з яких шукає свій унікальний візерунок.input_shape=(256,256, 3): Дуже важливо! Тільки для першого шару ми вказуємо, якого розміру зображення будуть надходити на вхід (256x256 пікселів, 3 канали для кольорів R, G, B).
Activation('relu'): Це "активатор". Він вирішує, чи є знайдений візерунок достатньо важливим, щоб передати його далі. relu — це просте правило: якщо сигнал позитивний — пропускаємо, якщо ні — блокуємо.MaxPooling2D(pool_size=(2, 2)): Це шар "узагальнення" або "стиснення". Він зменшує розмір зображення вдвічі, залишаючи тільки найяскравіші пікселі з кожної ділянки 2x2. Це допомагає моделі зосередитись на найважливіших ознаках і працювати швидше.- Цикл
for: Оскількиnum_conv_layersу нас дорівнює 2, а один шар ми вже додали, цей цикл виконається один раз (2-1=1) і додасть ще один такий самий блок:Conv2D->Activation->MaxPooling2D.
| In [9] |
|
/usr/local/lib/python3.11/dist-packages/keras/src/layers/convolutional/base_conv.py:113: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.
super().__init__(activity_regularizer=activity_regularizer, **kwargs)
|
Блок повнозв'язних шарів (прийняття рішень)
-
model.add(Flatten()): Цей шар виконує просту, але критичну роботу. Він бере двовимірну карту ознак (результат роботи згорткових шарів) і "розплющує" її в один довгий одновимірний вектор (список чисел). Це необхідно, щоб передати дані на наступний тип шарів. -
Dense(layer_size): Це повнозв'язний шар — класичний шар нейронної мережі. Він отримує список чисел і намагається знайти в них складніші залежності, комбінуючи прості ознаки, знайдені раніше.
| In [10] |
|
Вихідний шар (фінальний вердикт)
model.add(Dense(3))– це фінальний шар. Кількість нейронів у ньому завжди дорівнює кількості класів, які ми хочемо розпізнати. Оскільки у нас 3 папки з зображеннями, то тут число 3.model.add(Activation('softmax'))– це спеціальний активатор для вихідного шару. Він бере виходи з трьох нейронів і перетворює їх на ймовірності. Наприклад, якщо на виході буде [0.1, 0.8, 0.1], це означає, що модель на 10% впевнена, що це перший клас, на 80% — що другий, і на 10% — що третій.
| In [11] |
|
Компіляція моделі
Перш ніж почати навчання, ми маємо "скомпілювати" модель, давши їй три речі:
loss='categorical_crossentropy'– функція втрат, яка вимірює, наскільки сильно модель помилилася;categorical_crossentropy— стандартний вибір для задачі класифікації на кілька класів.optimizer='adam'– оптимізатор, тобто алгоритм, який оновлює внутрішні параметри моделі, щоб зменшити її помилку (loss); adam — це надійний та ефективний вибір.metrics=['accuracy']– метрика, за якою будемо оцінювати успішність моделі під час навчання; accuracy (точність) показує, який відсоток зображень модель класифікувала правильно.
| In [12] |
|
Тренування моделі
Параметри, необхідні для процесу навчання:
model.fit(): "Навчити модель".training_data: навчальні дані, які ми підготували в попередньому блоці коду.epochs=num_training_epochs: повторити процес навчання 20 разів.validation_data = testing_data: після кожної епохи навчання на тренувальних даних, модель буде проходити "іспит" на тестових даних. Це дозволяє нам бачити, чи модель дійсно вчиться, чи просто "зазубрює" відповіді (що називається перенавчанням).
| In [13] |
|
/usr/local/lib/python3.11/dist-packages/keras/src/trainers/data_adapters/py_dataset_adapter.py:121: UserWarning: Your `PyDataset` class should call `super().__init__(**kwargs)` in its constructor. `**kwargs` can include `workers`, `use_multiprocessing`, `max_queue_size`. Do not pass these arguments to `fit()`, as they will be ignored. self._warn_if_super_not_called() |
Epoch 1/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 11s 4s/step - accuracy: 0.2735 - loss: 2.8465 - val_accuracy: 0.3333 - val_loss: 1.0977 Epoch 2/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 7s 2s/step - accuracy: 0.4094 - loss: 1.0859 - val_accuracy: 0.3333 - val_loss: 1.3964 Epoch 3/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 8s 2s/step - accuracy: 0.3856 - loss: 1.1124 - val_accuracy: 0.3333 - val_loss: 1.0927 Epoch 4/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 7s 2s/step - accuracy: 0.4109 - loss: 1.0713 - val_accuracy: 0.3333 - val_loss: 1.1660 Epoch 5/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 8s 3s/step - accuracy: 0.4955 - loss: 1.2567 - val_accuracy: 0.5333 - val_loss: 1.2161 Epoch 6/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 7s 2s/step - accuracy: 0.7701 - loss: 0.8765 - val_accuracy: 0.4000 - val_loss: 1.9320 Epoch 7/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 10s 2s/step - accuracy: 0.6205 - loss: 0.9189 - val_accuracy: 0.4667 - val_loss: 1.1519 Epoch 8/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 8s 2s/step - accuracy: 0.5089 - loss: 0.8395 - val_accuracy: 0.4000 - val_loss: 1.1505 Epoch 9/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 7s 2s/step - accuracy: 0.4979 - loss: 0.8685 - val_accuracy: 0.4000 - val_loss: 1.6281 Epoch 10/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 10s 2s/step - accuracy: 0.5300 - loss: 0.8221 - val_accuracy: 0.5333 - val_loss: 0.8896 Epoch 11/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 8s 3s/step - accuracy: 0.8000 - loss: 0.7875 - val_accuracy: 0.4000 - val_loss: 2.0289 Epoch 12/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 7s 2s/step - accuracy: 0.6548 - loss: 0.6990 - val_accuracy: 0.8000 - val_loss: 0.7963 Epoch 13/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 8s 2s/step - accuracy: 0.6047 - loss: 0.7257 - val_accuracy: 0.7333 - val_loss: 0.8071 Epoch 14/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 9s 4s/step - accuracy: 0.6562 - loss: 0.5537 - val_accuracy: 0.6667 - val_loss: 1.2815 Epoch 15/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 7s 2s/step - accuracy: 0.7617 - loss: 0.5552 - val_accuracy: 0.4667 - val_loss: 1.6433 Epoch 16/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 8s 2s/step - accuracy: 0.8809 - loss: 0.3963 - val_accuracy: 0.5333 - val_loss: 1.3006 Epoch 17/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 7s 2s/step - accuracy: 0.8547 - loss: 0.4056 - val_accuracy: 0.5333 - val_loss: 1.3570 Epoch 18/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 8s 3s/step - accuracy: 0.8619 - loss: 0.3608 - val_accuracy: 0.6000 - val_loss: 1.1740 Epoch 19/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 7s 3s/step - accuracy: 0.9118 - loss: 0.3102 - val_accuracy: 0.5333 - val_loss: 1.5078 Epoch 20/20 3/3 ━━━━━━━━━━━━━━━━━━━━ 8s 2s/step - accuracy: 0.9066 - loss: 0.2551 - val_accuracy: 0.5333 - val_loss: 1.5419
| Out [13] |
|
Збереження моделі
Цей файл містить всю архітектуру моделі та всі її натреновані "знання". Тепер ми можемо в будь-який момент завантажити цей файл і використовувати готову модель для розпізнавання нових зображень, не проходячи процес навчання заново.
| In [14] |
|
WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`.
|
Тестування моделі
Модель навчена та збережена на комп'ютері (в тій самій папці, що й цей блокнот). Останній рядок надрукованого вище виводу містить точність як для навчальних даних, так і для даних валідації або тестування. Зверніть увагу на значення val_accuracy в останньому рядку, яке відповідає точності на зображеннях, на яких модель не навчалася. Це найкращий показник продуктивності оцінювача на інших зображеннях.
Наступна функція make_prediction приймає шлях до файлу фотографії ґрунту як вхідні дані та виводить класифікацію, яку передбачила модель. З тестової папки скопіюйте шлях до файлу в змінну test_image_filepath у другій комірці. Спробуйте кілька фотографій і подивіться, як поводиться модель.
Примітки:
- зазначимо, що
cv2завантажує зображення з порядком кольорів BGR (Синій-Зелений-Червоний), аpltочікує RGB (Червоний-Зелений-Синій). Код[:,:,[2,1,0]]міняє місцями синій та червоний канали, щоб кольори на екрані виглядали природно. img- завантаження зображення за допомогою інструментів Keras, де головним єtarget_size = (256,256), який змінює розмір зображення до 256x256 пікселів, бо саме на таких зображеннях тренувалася наша модель.img_batch– оскільки модель отримує дані пакетами (батчами), навіть якщо в пакеті лише одне зображення, то ця команда додає ще один вимір на початку, перетворюючи наш масив з розміру (256, 256, 3) на (1, 256, 256, 3). Тепер є "пакет" з одного зображення.class_– модель дає відповідь у вигляді числа (0, 1 або 2), а цей список допоможе перетворити число на зрозуміле слово. Порядок тут дуже важливий і має відповідати тому, як Keras проіндексував папки під час тренування.model.predict(img_batch)– повертає масив ймовірностей у відповідь на підготовлений пакет з зображенням, наприклад [0.1, 0.85, 0.05]. Це означає: "10% ймовірність, що це Gravel, 85% — що Sand, і 5% — що Silt"..argmax()– знаходить індекс (позицію) найбільшого числа в масиві. Для [0.1, 0.85, 0.05] найбільше число стоїть на позиції 1 (нумерація починається з 0).class_[...]– на підставі отриманого індекса визначається елемент зі спискуclass_. Наприклад, 1 – а цеclass_[1], що, в свою чергу, дає "Sand".
true_value– це хитрий спосіб перевірити, чи права модель. Він передбачає, що правильна відповідь міститься у назві файлу:re.search(...)– використовує регулярні вирази для пошуку першого зі слів "Gravel", "Sand" або "Silt" у рядкуimage_fp(шляху до файлу).
| In [15] |
|
| In [16] |
|
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 131ms/step Predicted Soil Type: Sand True Soil Type: Sand Correct?: True

Класифікація ґрунтів у відсотках
Ґрунти не є ідеально однорідними (повністю одного типу). Ґрунти часто є сумішшю типів і їх краще представити у відсотках. Наприклад, у клітинці нижче показано тестове фото з позначкою "Silt".
| In [17] |
|
|
Out [17] |
|
На цьому фото є трохи гравію, проте, схоже, що на одному фото є пісок, гравій та мул. Щоб краще класифікувати це зображення, створіть пропорцію для кожної мітки. Наприклад, це фото може бути 30% гравію, 20% піску та 50% мулу.
Розділіть фотографію на багато менших сегментів або квадратів та навчіть класифікатор на менших квадратах. Перейдіть по фотографії, щоб класифікувати кожен маленький квадрат та взяти пропорцію квадратів, що стосується гравію, піску та мулу. Ця пропорція потім перетворюється на відсоток відповідного типу ґрунту.
Дані
Виконайте дії, наведені нижче, щоб розділити існуючі навчальні фотографії (zip, 3 MB) на менші сегменти. Новий каталог називатиметься train_divided та test_divided.
Для навчання моделі краще мати багато маленьких, різноманітних прикладів, ніж кілька великих і однотипних.
Нижче визначена функція працює як автоматичний "різак для фотографій". Вона бере кожне велике зображення і нарізає його на безліч маленьких квадратних шматочків.
Результат полягає у тому, що з одного великого фото (розміром, скажімо, 1024x768) отримаємо сотні маленьких зображень (кожен розміром 64x64). Це значно збільшує наш набір даних для тренування, що робить модель розумнішою та стійкішою.
Ми визначаємо функцію split_images, яка приймає два аргументи:
image_dir– шлях до папки, де лежать вихідні великі зображення, розсортовані за класами.save_dir– шлях до папки, куди ми будемо зберігати нарізані маленькі зображення.
Ця функція — це ефективний конвеєр, який автоматизує рутинну, але важливу роботу:
- Бере папку з великими фото.
- Проходить по кожному класу (Gravel, Sand, Silt).
- Бере кожне велике фото всередині класу.
- Нарізає його на сітку маленьких квадратиків 64x64.
- Зберігає кожен повноцінний квадратик у відповідну папку для оброблених даних.
| In [18] |
|
Примітка: За допомогою write_path = ... створюємо унікальний шлях для збереження файлу. Він складається з:
save_folder: папки для цього класу.str(randrange(100000)): випадкового числа, щоб уникнути збігу імен.img{r}_{c}.jpg: координат r та c, з яких був вирізаний цей шматок. Це корисно для відстеження.
Наступний блок коду ставить на меті підготовку робочого простору перед тим, як запускати основну функцію нарізки зображень (split_images). Оскільки багато маленьких фотографій треба буде розкласти по папках, які треба спочатку створити та підписати. А вже потім робити нарізку.
Отже, код виконує такі операції:
- Створює нову структуру папок: Він створює набір порожніх папок (
train_divided,test_divided) з відповідними підпапками для кожного класу (Gravel, Sand, Silt). - Обчислення батьківської директорії
parent = training_data_directory.replace('train', '')* Береться шлях до тренувальної папки і замінюється підрядок "train" на порожній, фактично піднімаючись на рівень вище. Це зручно, щоб далі створити в тому ж корені папки train_divided та test_divided. * Методstr.replace(old, new)повертає новий рядок з підстановкою підрядка й не змінює оригінальний рядок. - Списки нових директорій та класів *
dirs = ['train_divided', 'test_divided']— цільові папки, куди буде покладено розділені зображення тренувального та тестового наборів. *class_ = ["Gravel", "Sand", "Silt"]— імена класів. Для кожної цільової директорії будуть створені підпапки з такими назвами. - Створення структури папок * Зовнішній цикл
os.mkdir(os.path.join(parent, dir))створюєdata/soil_images/train_dividedтаdata/soil_images/test_divided. * Внутрішній цикл створює підпапки класів у кожній з цих директорій: наприклад,data/soil_images/train_divided/Gravel,data/soil_images/train_divided/Sand,data/soil_images/train_divided/Siltі аналогічно дляtest_divided. * Якщо будь-яка з директорій уже існує,os.mkdirпіднімеFileExistsError. Це буде спіймано у блоціexcept, тому код не впаде.
/data/soil_images/
├── train/
│ ├── Gravel/ (тут лежать великі вихідні фото)
│ ...
├── test/
│ ├── Gravel/ (тут лежать великі вихідні фото)
│ ...
├── train_divided/ <-- Створено кодом
│ ├── Gravel/ <-- Створено кодом
│ ├── Sand/ <-- Створено кодом
│ └── Silt/ <-- Створено кодом
└── test_divided/ <-- Створено кодом
├── Gravel/ <-- Створено кодом
├── Sand/ <-- Створено кодом
└── Silt/ <-- Створено кодом
- Запускає процес нарізки: Після того, як папки готові, він викликає функцію
split_images, щоб взяти великі зображення з вихідних папок і заповнити щойно створені папки маленькими нарізаними зображеннями.
image_dir=training_data_directory: брати великі зображення з папкиdata/soil_images/train/.save_dir=...: зберігати маленькі нарізані зображення в папкуdata/soil_images/train_divided/. Знову використовується.replace(), щоб автоматично сформувати правильний шлях.- Робимо абсолютно те саме, але для тестових даних: брати великі зображення з
data/soil_images/test/та зберігати маленькі нарізані зображення вdata/soil_images/test_divided/.
- Має "захист від помилок": Він обгорнутий у конструкцію try...except, щоб не видавати помилку, якщо ви запускаєте скрипт вдруге і папки вже існують.
try:: Код намагається виконати все, що знаходиться всередині цього блоку. except FileExistsError:: Якщо під час виконання try виникає конкретна помилка FileExistsError (яка трапляється, коли os.mkdir намагається створити папку, що вже існує), програма не "впаде" і не зупиниться. Замість цього вона перейде до блокуexcept.pass: Це команда, яка означає "нічого не робити". Тобто, якщо папки вже існують, програма просто проігнорує помилку і спокійно продовжить роботу. Це робить скрипт зручним для повторного запуску.
| In [19] |
|
Завантажити модель
Якщо кількість вхідних пікселів змінюється, слід навчити нову модель або масштабувати зображення до початкових навчальних розмірів. Для цілей цієї демонстрації повторне навчання не потрібне, оскільки фотографії масштабуються до 1024x1024 перед субдискретизацією 256x256 блоків (16) у кожному зображенні.
| In [20] |
|
WARNING:absl:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. |
/content/soil.h5
Класифікація зображень
classify_images бере зображення та модель і перебирає кожен квадрат розміром 256x256. Вона класифікує кожен квадрат і додає значення до лічильника, щоб створити дробовий прогноз ґрунту. Функція виводить частку кожного типу ґрунту, який було класифіковано.Більш детальний опис процедури класифікації
- Функція
classify_percentage('path/to/my_large_image.jpg')запускає таймер і викликаєclassify_images. - Функція
classify_imagesзавантажує велике зображення, змінює його розмір до 1024x1024 і починає нарізати його на 16 шматочків (4x4) розміром 256x256. Для кожного з 16 шматочків вона викликаєmodel_classify. - Функція
model_classifyбере шматочок, готує його (масштабує, додає вимір) і отримує від моделі прогноз (наприклад, 'Gravel'). Цей прогноз повертається назад доclassify_images. - Функція
classify_imagesотримує 'Gravel' і збільшує лічильник gravel_count. Цей процес повторюється для всіх 16 шматочків. - Після аналізу всіх шматочків
classify_imagesобчислює фінальні пропорції (наприклад, [0.25, 0.625, 0.125]) і повертає їх. - Функція
classify_percentageотримує цей масив, зупиняє таймер, показує вихідне зображення і друкує фінальний звіт у відсотках.
Функція
model_classify — наш "експерт", який вміє дивитися тільки на один маленький шматочок зображення (розміром 256x256) і казати, до якого класу він належить.
Кроки:
- Підготовка: Функція отримує на вхід один вирізаний шматочок cropped_img. Вона виконує ті самі кроки підготовки, що й під час тренування: масштабує пікселі (/ 255.) і додає фіктивний вимір "пакету" (np.expand_dims), бо модель predict очікує на вхід саме такий формат.
- Прогноз: Підготовлений шматочок передається моделі (model.predict). Модель повертає масив ймовірностей, наприклад [0.1, 0.2, 0.7].
- Інтерпретація: Метод np.argmax() знаходить індекс елемента з найвищою ймовірністю (у нашому прикладі це індекс 2). Потім цей індекс використовується для отримання назви класу зі списку classes (індекс 2 відповідає 'Silt').
- Повернення результату: Функція повертає назву класу у вигляді рядка (наприклад, 'Silt').
| In [21] |
|
Функція classify_images — "керівник", який організовує роботу. Вона бере велике зображення, нарізає його на завдання (маленькі шматочки) і роздає їх "експерту" (model_classify). Потім вона збирає всі відповіді і підраховує підсумкову статистику.
| In [22] |
|
classify_percentage бере дані від classify_images, красиво їх оформлює, додає візуальний контекст (саме зображення) і представляє кінцевому користувачеві у зрозумілому вигляді.
| In [23] |
|
| In [24] |
|
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 113ms/step [0.7133175 0.08069583 0.20598671] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 57ms/step [0.7157452 0.06372937 0.22052544] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 59ms/step [0.6452865 0.05052679 0.30418676] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 54ms/step [0.5388591 0.02831377 0.43282714] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 53ms/step [0.69516265 0.04459155 0.26024577] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 54ms/step [0.6976294 0.0370199 0.26535076] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 54ms/step [0.6241521 0.02753545 0.3483124 ] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 54ms/step [0.3350818 0.01379307 0.65112513] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 61ms/step [0.6757018 0.0457616 0.27853662] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 55ms/step [0.70627993 0.04256658 0.25115347] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 60ms/step [0.5881671 0.03107259 0.3807604 ] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 56ms/step [0.35478234 0.01494657 0.6302711 ] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 56ms/step [0.6031833 0.05062249 0.34619412] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 56ms/step [0.6187473 0.05031257 0.3309401 ] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 57ms/step [0.5872765 0.04620933 0.36651415] 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 60ms/step [0.44831035 0.02512084 0.52656883] --- Gravel: 13 Sand: 0 Slit: 3 --- Percent Gravel: 81.25%) Percent Sand: 0.0%) Percent Silt: 18.75%) Time to Classify: 1.93016 seconds ---
Чи відповідає відсоток класифікації фотографії?
Обидва підходи до класифікації ґрунту мають переваги. Наприклад, класифікація всього зображення є швидшою. Однак, відсоткова класифікація є більш обчислювально витратною, але надає більше інформації та може бути кращим відображенням справжньої класифікації.